The XML DOM uses a tree-structure, also known as a node-tree, to view an XML document, i.e., each node can be accessed through the tree. We can also modify, delete, or create a new element through the tree. The getElementsByTagName() method and the childNodes property returns a list of nodes.
DOM Node List:
The childNodes or getElementsByTagName() properties or methods is used to return a node list object. A list of nodes is represented by the node list object in the same order as in the XML. The index numbers starting from 0 are used to access the nodes in a node list.
Books.xml:
ABC Author Name 2020 100.00 XQuery Book Author 1 Author 2 Author 3 Author 4 2004 350.00
Example: To return a node list of title elements in “books.xml” which is loaded into the variable xmlDoc:
x = xmlDoc.getElementsByTagName("title");
Explanation:
Here, x becomes a node list object, after the execution of the above code.
Example: To return the text from the first <title> element in the node list (x):
Output:
![]()
Explanation:
In the above example, the value of the “txt” variable becomes “ABC”, after the execution of the above code.
Node List Length:
By keeping itself up-to-date, a node list object automatically updates the list, if an element is deleted or added. The number of nodes in a list represents the length property of a node list. For looping through each element in a list, the length of the node list can be used.
Example: To return the number of <title> elements in “books.xml”:
x = xmlDoc.getElementsByTagName('title').length;
Explanation:
Here, the value of x will be 2, after the execution of the above code.
Example: Using the length property to loop through the list of <title> elements:
Output:
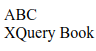
Explanation:
In the above example, we are loading the “books.xml” into xmlDoc. To hold a node list of all title elements, we will set the x variable. The text node values can be collected from the <title> elements.
DOM Attribute List (Named Node Map):
To get a list of the attribute nodes, the attributes property of the element node is used, also called a named node map. It is similar to a node list. However, there are some differences in methods and properties. By keeping itself up-to-date, an attribute list automatically updates the list, if an attribute is deleted or added.
Example: To get a list of attribute nodes from the first <book> element in “books.xml”:
x = xmlDoc.getElementsByTagName('book')[0].attributes;
Explanation:
In the above example, x.length represents the number of attributes, after the execution of the code. Also, to return an attribute node, the x.getNamedItem() can be used.
Example: To get the value of the “category” attribute, and the number of attributes of a book:
Output:
Child 1
Explanation:
In the above example, the “books.xml” is loaded into xmlDoc. Now, to hold a list of all attributes of the first <book> element, we will set the x variable. The value of the “category” attribute and the length of the attribute list can then be retrieved.